In questo articolo esploreremo le differenze tra le architetture Lakehouse e Warehouse offerte da Microsoft Fabric, per scegliere la soluzione più adatta alle nostre esigenze.
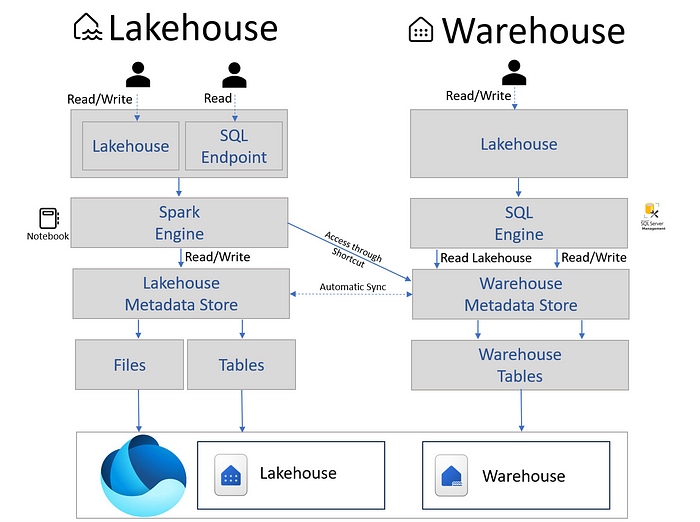
Entrambe le architetture memorizzano i dati in OneLake nel formato open source Delta/Parquet. Tuttavia, presentano caratteristiche diverse che le rendono adatte a scenari differenti.
Lakehouse
Microsoft Fabric Lakehouse è una piattaforma che consente di archiviare, gestire e analizzare dati strutturati e non strutturati in un’unica posizione. Utilizza il formato di file Parquet Delta e permette di archiviare i dati in due posizioni fisiche predefinite:
Files (tabelle non gestite o unmanaged)
Tables (tabelle gestite o managed)
Managed Table: Queste tabelle sono gestite internamente da Spark, che controlla sia i dati che i metadati. I dati sono memorizzati in una directory designata e i metadati in un metastore. L’eliminazione di una tabella gestita comporta la perdita sia dei dati che dei metadati.
Unmanaged Table: In queste tabelle, Spark gestisce solo i metadati, mentre l’utente è responsabile della gestione della posizione dei dati, che rimangono esterni all’ecosistema Spark. L’eliminazione di una tabella non gestita rimuove solo i metadati; i dati rimangono intatti.
Folder “Files”: Memorizza qualsiasi tipo di file, inclusi CSV, Parquet, immagini, video, ecc.
Folder “Tables”: Memorizza tabelle in formato Delta, disponibili per l’interrogazione tramite l’endpoint SQL di Fabric Lakehouse e per scenari Direct Lake con Power BI.
Fabric crea automaticamente un endpoint SQL collegato alla cartella Tables al momento della creazione di un Lakehouse. Questo endpoint consente di analizzare i dati Delta utilizzando comandi T-SQL e di implementare misure di sicurezza SQL. Tuttavia, opera in modalità di sola lettura sulle tabelle Delta.
Approccio Spark-centrico: Le operazioni sui dati nel Lakehouse avvengono tramite notebook Spark, utilizzando linguaggi come PySpark, SQL, ecc.
Warehouse
In Microsoft Fabric, il Warehouse è un data warehouse tradizionale che supporta transazioni, query DDL e DML, viste, funzioni e stored procedure. I dati nel Warehouse sono archiviati nel formato Parquet e gestiti tramite Delta Lake, garantendo transazioni ACID.
Disaccoppiamento di calcolo e storage: Il Warehouse utilizza un’infrastruttura serverless che permette una scalabilità infinita e dinamica delle risorse, con la possibilità di allocare risorse fisiche di elaborazione in pochi millisecondi. Questo consente a più motori di calcolo di leggere da qualsiasi fonte di storage supportata.
Approccio SQL-centrico: Le operazioni nel Warehouse avvengono tramite T-SQL, con supporto per multi-table transactions, mascheramento dinamico dei dati e altre funzionalità avanzate di Data Warehouse.
Accesso ai dati tra Lakehouse e Warehouse
È possibile accedere ai dati tra Lakehouse e Warehouse se entrambi si trovano nello stesso workspace Fabric.
Accesso a Lakehouse da Warehouse: Utilizzando query cross-database, possiamo interrogare i dati di Lakehouse dal Warehouse con T-SQL.
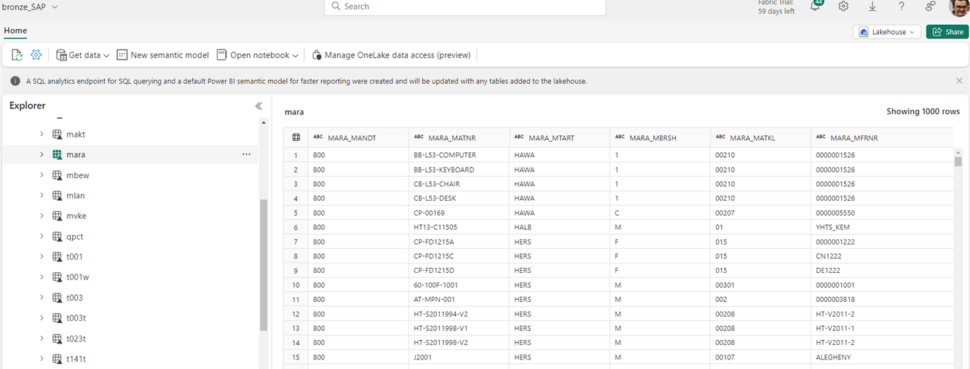
Sotto vediamo un esempio reale basato su dati SAP tramite il nostro ERP Gateway che gestisce un Lakehouse di nome bronze_SAP dove vengono gestiti i dati grezzi
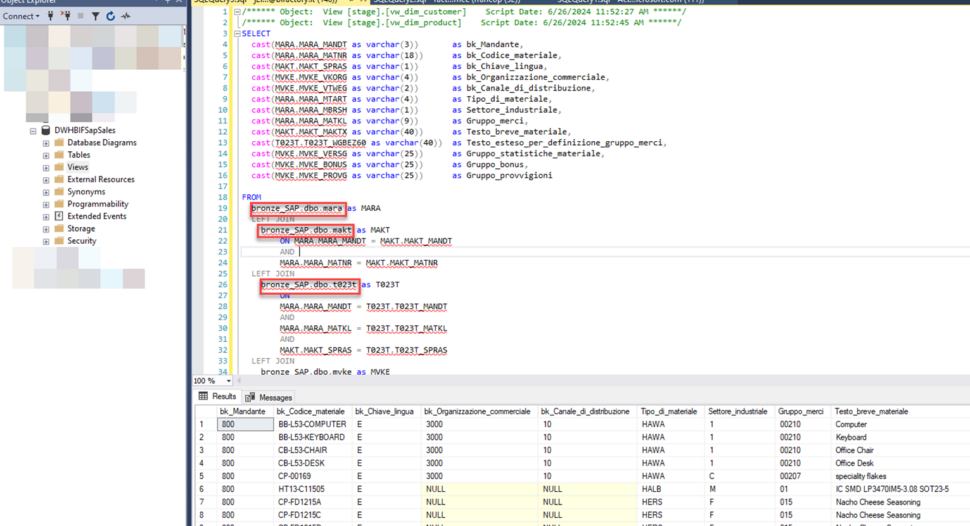
e come sono accessibili da un Warehouse di nome DWHBIFSapSales
Accesso a Warehouse da Lakehouse: Creando shortcut (è una virtualizzazione del dato che permetter di leggere il dato nel sua forma originaria senza duplicarlo.
EDIT
A fine Giugno 2024 Microsoft ha introdotto un’importante novità da tenere in considerazione nelle scelte architetturali: si tratta della disponibilità dello Spark Connector for Fabric Data Warehouse (DW) per un nativo accesso dal Lakehouse.
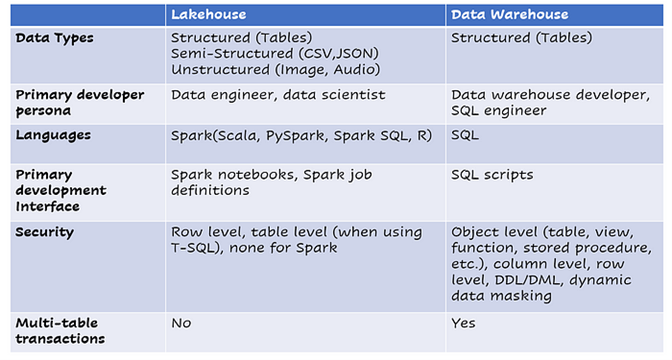
Differenze tra Lakehouse e Warehouse
Dopo aver visto le caratteristiche possiamo approcciare quale dei 2 possa rispondere meglio alle nostre esigenze.
Differenze e considerazioni per la scelta
Quando scegliere il Warehouse:
Dati strutturati o semi-strutturati.
Team con competenze T-SQL e Data Warehousing.
Migrazione da un Data Warehouse esistente.
Necessità di funzioni avanzate come Multi-table transactions.
Necessità di modificare i dati dopo la normalizzazione o trasformazione.
Quando scegliere il Lakehouse:
Dati non strutturati o semi-strutturati.
Team con competenze in Spark.
Nessuna necessità di funzioni avanzate di Data Warehouse.
Preferenza per operazioni Spark rispetto a T-SQL.
Spesso, un’architettura che combina Lakehouse e Warehouse può sfruttare il meglio di entrambi i mondi e in effetti, vedendo le effettive esigenze in più di un caso, è una configurazione che ci troviamo a suggerire spesso ai clienti che seguiamo in Bi Factory. Il livello di consumo (tramite Power BI o l’endpoint SQL del Warehouse) può utilizzare il Warehouse, mentre le attività di staging e preparazione dei dati possono avvenire tramite il Lakehouse. Sotto un esempio di questo approccio.